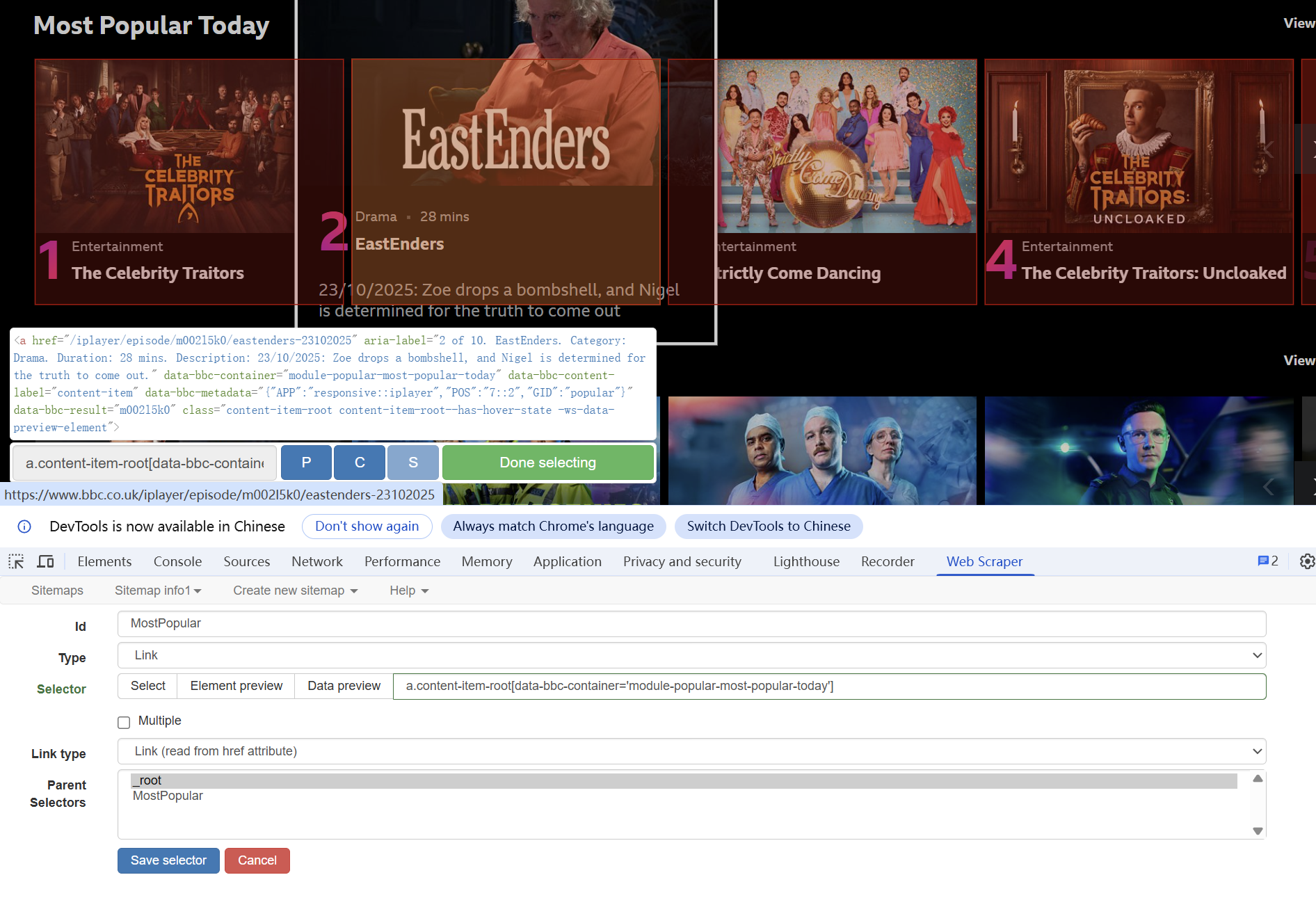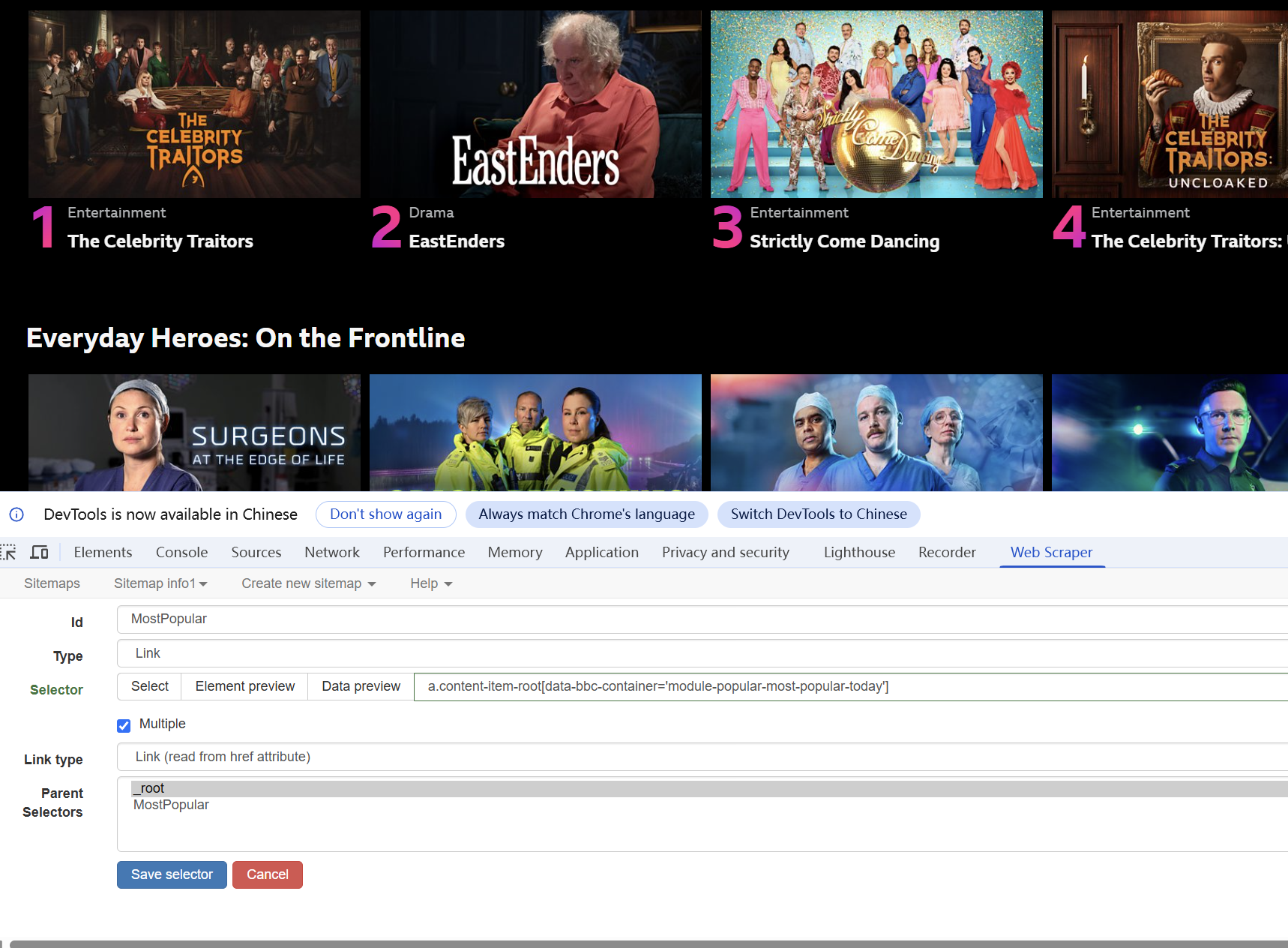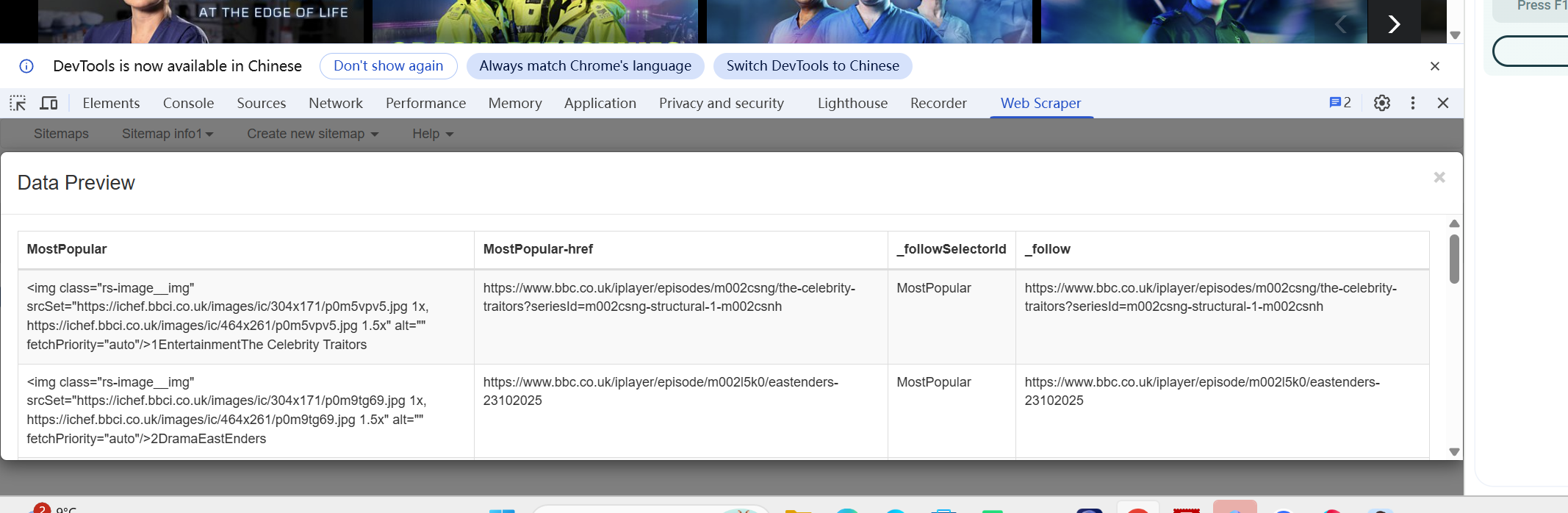










This week, we learned how to use web crawlers—a specialized tool designed to collect targeted data from websites, such as video file sizes and durations on streaming platforms. Compared with manual data collection, web crawlers drastically enhance the efficiency of data acquisition and integration, laying a solid foundation for subsequent analytical processes. For instance, if we aim to obtain the list of films in this year’s Douban Top 250, crawlers can automatically extract the required information, eliminating the tediousness of repetitive manual operations (Zhang et al., 2021). This efficient data-gathering method enables large-scale data analysis, empowering users to quickly uncover valuable insights hidden within the data.
Here's the process we followed:
- First, open the scraper tool
- Create a new sitemap and a new selector, linking the type of data you want to collect
- Save the selector and open the data preview to check the results
However, the use of web crawlers poses significant ethical challenges. Firstly, much of the data on platforms constitutes proprietary information exclusive to companies, embodying their operational investments and intellectual property rights. Unauthorized crawling of such data essentially infringes on these proprietary rights, violating platform management rules and ethical norms (Gillespie, 2018). Secondly, unrestricted use of web crawlers continuously consumes server bandwidth and computing resources. This excessive resource depletion may exceed the platform’s load capacity, hindering normal access for regular users—an abuse of shared network resources that contradicts the principles of rational regulation in the sharing economy (Erickson & Sørensen, 2016). Such practices not only disrupt platform operations but also undermine the rights and interests of other users, highlighting the need for ethical restraint in crawler usage.